15.2 Propensity scores
- Estimating PS
- PS histogram
- PS density plot
- PS summary
- Fitting outcome regression model with PS as a covariable
- Outcome regression model with PS as a covariable
fit <- glm(qsmk ~ sex + race + age + I(age*age) + education + smokeintensity + I(smokeintensity*smokeintensity) + smokeyrs + I(smokeyrs*smokeyrs) + exercise + active + wt71 + I(wt71*wt71), data = data, family = binomial())data %<>% mutate( ps = predict(fit, type = "response", newdata = .))data %>% ggplot(aes(x = ps, color = as.factor(qsmk), fill = as.factor(qsmk))) + geom_histogram(alpha = 0.2, bins = 30) + # facet_grid(rows = vars(qsmk)) + theme_minimal(base_size = 12)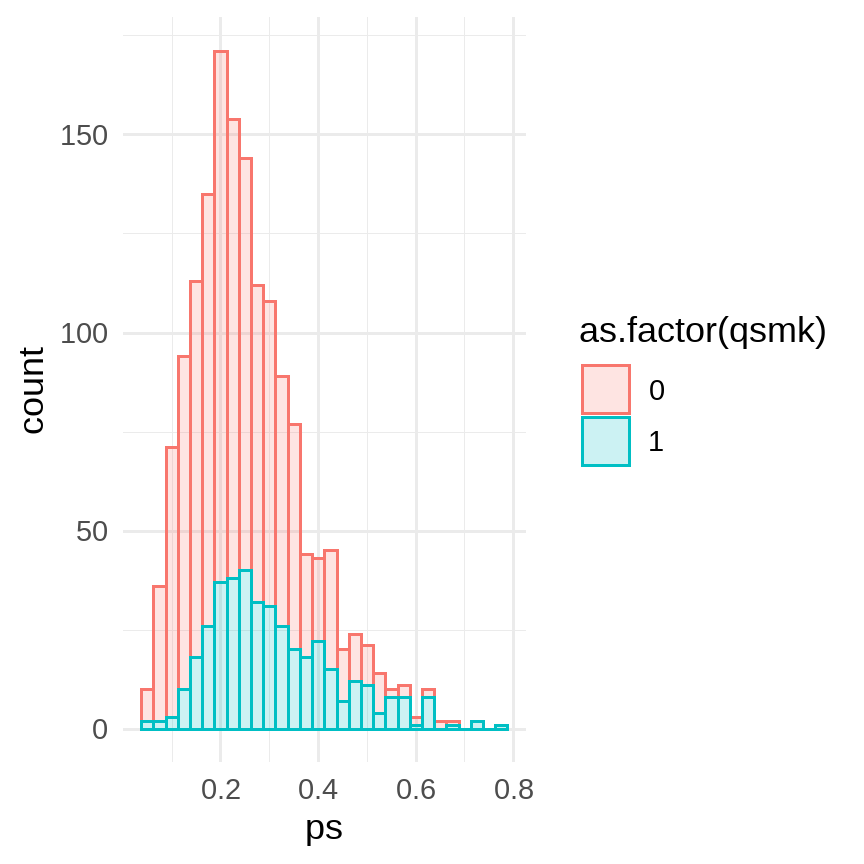
data %>% ggplot(aes(x = ps, color = as.factor(qsmk), fill = as.factor(qsmk))) + geom_density(alpha = 0.2) + # facet_grid(rows = vars(qsmk)) + theme_minimal(base_size = 12)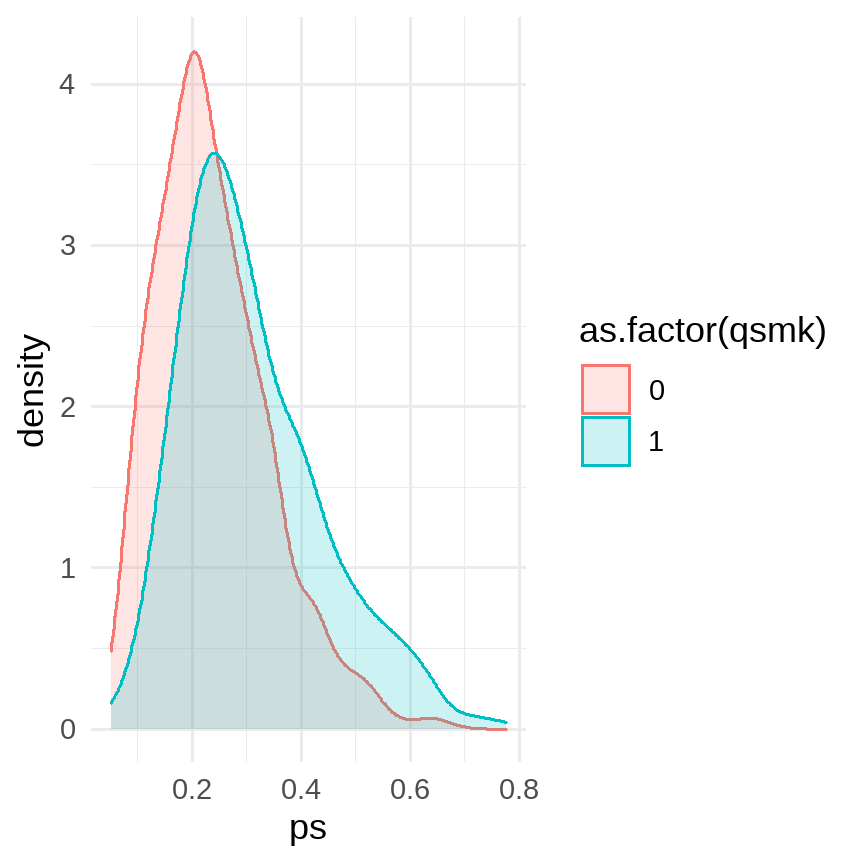
data %>% group_by(qsmk) %>% summarise(min = min(ps), mean = mean(ps), median = median(ps), max = max(ps))## # A tibble: 2 x 5## qsmk min mean median max## <dbl> <dbl> <dbl> <dbl> <dbl>## 1 0 0.0510 0.239 0.222 0.681## 2 1 0.0599 0.309 0.282 0.777fit <- glm(data = data, formula = wt82_71 ~ qsmk + ps) %>% broom::tidy(conf.int = T)fit %>% filter(term == "qsmk")## # A tibble: 1 x 7## term estimate std.error statistic p.value conf.low conf.high## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>## 1 qsmk 3.45 0.460 7.52 9.41e-14 2.55 4.35# Hernan: model without any product terms yielded the estimate 3.5 (95% confidence interval: 2.6, 4.3) kg.